




























Before You Build: A Guide to Customer Intelligence In-House

Why the prototype misleads
In almost every organization that takes customer feedback seriously, the same proposal eventually lands on the table: we could build this ourselves. And it isn't a naive proposal. A capable engineering team, given some model budget and a few data exports, can stand up an internal tool that searches tickets, clusters themes, and answers questions in plain language. The demo is usually impressive. It usually wins the room.
The problem is that the demo is the cheapest, fastest, most flattering moment the project will ever have. Everything that determines whether the system is worth owning happens later, and most build-versus-buy decisions are made before anyone has priced what "later" looks like.
This brief is written to close that gap. It is not an argument that you cannot build customer intelligence in-house; a strong team plainly can. It is an argument for deciding with the full cost in view, so the choice holds up in front of a CFO, an IT review, and a board. Not just in front of a demo.
A demo proves the easy 20% works. Customer intelligence that an enterprise can actually run on is the other 80%: the parts that only reveal themselves once real data, real volume, and real stakeholders are involved.
Picture the difference concretely. The demo answers "what are customers saying about checkout?" against a clean export from one tool. The system has to answer the same question across nine sources, in four languages, deduplicated, attributed to the right speaker, weighted by account value, filtered to the people allowed to see each record, and consistent enough that two teams asking on two different days get the same number. None of that is visible in a demo. All of it is the actual work.
This is why internal builds rarely fail loudly. They keep returning answers. What erodes, quietly, over quarters, is whether anyone can still trust those answers, audit them, or keep them running as the business starts to depend on them.
The cost on a timeline
The most useful way to price a build is not as a one-time project but as a curve over time. Here is the shape that shows up again and again.
Day 1: The prototype
One or two engineers, a model API, and exports from your busiest channel. Within a sprint it clusters themes and answers questions. Confidence is high and cost looks trivial. This is the moment the decision usually gets made, and the moment the least is actually known.
Month 6: The connector tax
The first few sources go in smoothly. The next dozen expose every edge case in normalization, deduplication, and schema drift, and each one needs backfill, retry logic, and provenance clean enough to trace any answer to its raw record.
Raw text also turns out not to be signal. A single ticket can carry a bug, a workaround, a feature request, and a churn warning at once, mixed with agent replies and internal notes. Without careful parsing and speaker attribution, the metrics look precise and are quietly wrong. By now the team is maintaining pipelines, not producing intelligence.
Month 12: The trust reckoning
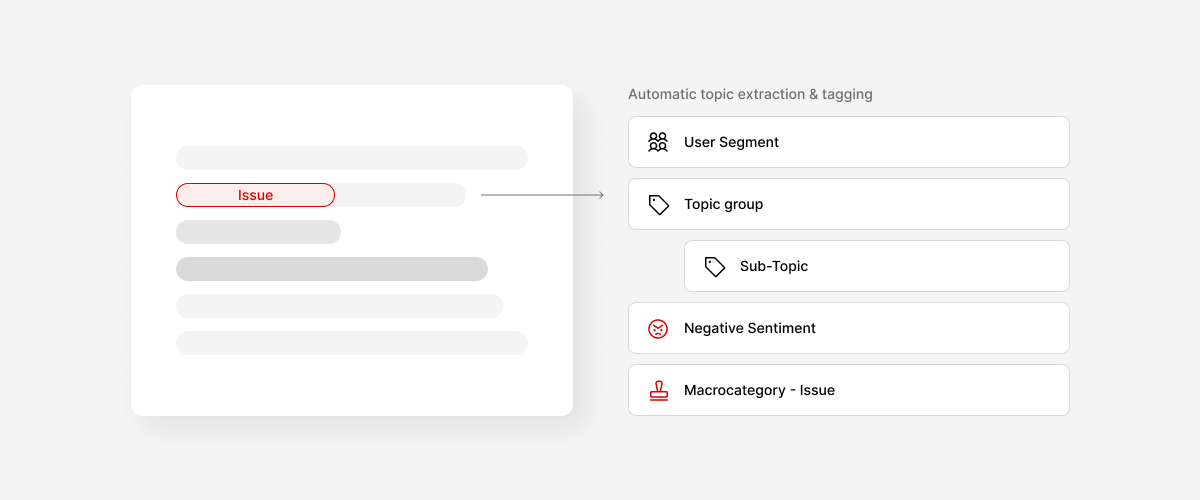
The conversational layer ships and answers confidently, sometimes from a stale source or a skewed sample. The first hallucination a leader notices is expensive, because trust is hard to rebuild. Underneath it sit two problems most teams defer: a governed, versioned taxonomy (without it, "billing" and "performance" become meaningless catch-alls) and an evaluation framework (without it, nobody can prove whether quality is improving or sliding).
Governance arrives on the same timeline, usually via the first enterprise security review. Customer feedback is full of personal data, and retrofitting controls is far harder than designing them in.
97% of organizations that suffered an AI-related breach lacked proper access controls; 63% had no AI governance policy at all, and "shadow AI" added ~$670K to the average breach. (IBM Cost of a Data Breach 2025)
Year 2: The compounding bill
Nothing holds still. Sources change, models change, the taxonomy evolves, history needs reprocessing, compliance shifts, and every team (CX, Support, Product, Success, Sales, leadership) adds reasonable requirements. The model bill itself becomes a real operating line: not just chat queries, but backfills across millions of records, reclassification after every taxonomy change, and continuous evaluation.
This is also where the staffing reality lands. A system at this level is not a side project for one AI engineer; sustaining it draws on data engineering, backend, ML, product, design, security, and dedicated taxonomy operations. The build wasn't expensive because it was hard to start. It's expensive because it never stops.
40%+ of agentic AI projects will be canceled by the end of 2027, driven not by the technology but by escalating cost, unclear value, and inadequate risk controls. (Gartner, 2025)
The reframe that makes the decision easy
The build-versus-buy question is usually posed as "can we build it?" The more useful question is "what are we committing to own forever?" Because the deliverable is not an application. It is an operating model: a standing team, a governance burden, a model bill, and a maintenance obligation that compounds for as long as the business uses it.
Framed that way, the broader market data stops being abstract and starts being a warning about exactly this gap: the distance between a system that demos and a system that delivers durable value at scale.
88% → 6%: 88% of organizations use AI, but only ~6% are high performers tying 5%+ of EBIT to it, and nearly two-thirds haven't begun scaling it across the enterprise. (McKinsey, State of AI 2025)
The lesson is not "never build." It is "build at the layer where building creates advantage, and buy the layer where it only creates cost."
Build: what is yours alone
- Workflows routing specific signals to specific teams
- Executive reporting tied to your planning cadence
- Quality monitors for a particular launch or surface
- Churn logic that blends feedback with your own health model
- Close-the-loop processes shaped to how your teams work
Buy: the non-differentiating substrate
- Multi-source ingestion and normalization
- PII handling, access control, audit, deletion
- Governed, versioned taxonomy and classification quality
- Customer & account context modeling
- Grounded, cited, evaluated conversational access
No enterprise gains a competitive edge from having built its own ingestion pipeline or its own PII redaction. It gains an edge from what it does with the resulting intelligence. That is the line worth drawing.
When building genuinely makes sense
A guide that only ever says buy isn't a guide, it's a pitch. There are real cases where building in-house is the right call, and they're worth naming clearly.
1. Customer intelligence is your product.
If the capability you're building is something you sell or license to your own customers: an embedded analytics layer, a white-label insights feature, a branded reporting module. It belongs in your core stack. Vendor dependency at the product layer creates margin risk, lock-in exposure, and customization ceilings you'll eventually hit. Build it, own it, differentiate it.
2. Your deployment constraints are genuinely unique.
Hard air-gap requirements, sovereign cloud mandates, or heavily regulated workflows (defence, critical national infrastructure, certain financial and healthcare contexts) can make external platforms genuinely non-viable rather than just inconvenient. The test is whether the constraint is architectural or organizational: "our security team prefers on-premise" is organizational and often negotiable; "we are legally prohibited from sending this data class outside a specific jurisdiction" is architectural and is not.
3. You hold proprietary context that is itself a moat.
Some organizations have feedback data so structurally unusual — a proprietary ontology accumulated over decades, a domain-specific classification system that took years to validate, a dataset that exists nowhere else — such that an external taxonomy would dilute rather than accelerate their insight. The honest version of this test: could a capable new analyst, given a good platform and six months, produce equivalent quality? If yes, the moat is shallower than it feels.
4. You can staff the entire operating model, not just the prototype.
This is the criterion most frequently skipped and most frequently regretted. Building a production system means committing, before the first line of code, to the team that will still be running it in year three: data engineers for pipeline reliability, ML engineers for model evaluation and retraining, a product owner for taxonomy governance, a security owner for compliance and audit, and someone whose job it is to keep stakeholders trusting the output. If the honest answer is "we'll figure that out after we see if it works," the prototype will probably work and the system probably won't.
If one or more of these genuinely describes your situation, build — and treat the layer-by-layer anatomy below as your minimum viable system map, not a stretch goal. If none of them do, the build math is quietly doing you a favor by staying invisible.
What to demand from any solution you buy
If you decide to buy rather than build, the goal is not to pick "an AI tool." It is to acquire the foundational layer so your own team is free to build the differentiated layer on top. Hold any candidate, internal or external, to the same bar:
- Multi-source ingestion that unifies every high-signal channel, not just the easy ones, with deduplication and source provenance.
- A governed, versioned taxonomy built around your product language, so reporting stays consistent and comparable over time.
- PII handling and access control built in: detection, redaction, role-based access, audit logs, deletion. Not bolted on after the first security review.
- Automatic enrichment (sentiment, intent, severity, request/bug markers) on every interaction, with an evaluation framework behind it.
- Grounded conversational access with citations, permission awareness, and drill-down to source. Not a chat box that answers from the wrong sample.
- Customer context joins that tie feedback to revenue, ACV, and account health, so the loudest issue doesn't beat the most important one.
- Workflow distribution and monitoring that pushes insight into the tools each team already uses, with ownership and follow-through.
Drawn this way, the line is clear: no enterprise gains a competitive edge from having built its own ingestion pipeline. It gains an edge from what it does with the resulting intelligence.
The system, layer by layer
For teams evaluating this seriously — the ones who have already asked "why not build it ourselves?" — here is the full anatomy of what a production system requires. Each layer is independently load-bearing; skip one and the system either drifts into noise or produces confident, wrong answers.
- Multi-source ingestion. Reliable connectors for support, CRM, surveys, reviews, app stores, and transcripts, each with backfill and schema-drift detection. Failure mode: feeds go stale and duplicates inflate the trend lines.
- Identity resolution. Tying people, accounts, deals, and segments together across systems. Failure mode: one customer splinters into many, or unrelated customers get merged.
- Privacy & compliance. Detection, redaction, retention, role-based access, audit logs, deletion before any AI step. Failure mode: workflows expose or retain data the company can't govern.
- Parsing & attribution. Turning messy threads into discrete, attributable, citable units of feedback. Failure mode: agent replies and customer complaints get blended.
- Governed taxonomy. Customer-specific themes, versioned so changes don't corrupt historical reporting, evaluated for drift. Failure mode: categories become junk drawers and the system loses authority.
- Classification & evaluations. Assigning every unit to taxonomy, sentiment, severity, intent, and measuring whether that's good enough to trust. Failure mode: nobody can prove the system is improving rather than degrading.
- Customer context joins. Connecting feedback to ARR, usage, NPS, churn risk, and custom business objects. Failure mode: a convenient join breaks silently when finance redefines ARR.
- Retrieval & conversational access. Permission-aware retrieval, hybrid search, citations, prompt-injection defenses over the full dataset. Failure mode: the interface hallucinates or answers from a biased sample.
- Workflow, governance & monitoring. Routing insight to the right owner, tracking it to completion, proving the outcome. Failure mode: insights become screenshots instead of owned work.
What the build math doesn't show
The cost of building in-house is usually calculated as a one-time project: engineering time, model API budget, and a few months of setup. That math is incomplete in at least five ways.
- Infrastructure at single-tenant cost. Every compute resource your internal system uses is paid at full price, for one workspace. A vendor distributes that same cost across dozens of clients. The per-unit economics are structurally different, and the gap compounds as data volume grows.
- Optimization as a discipline. Keeping inference costs under control requires ongoing expertise: model compression, quantization, batching strategies, pipeline orchestration with tools like Airflow. Teams that have spent years iterating on these problems build intuitions that a first implementation simply cannot shortcut into. Most internal teams staff for the build, not for this.
- Improvement requires your attention. An internal system gets better only when your team works on it. A platform that serves many clients improves every time any of those clients surfaces a new edge case, a new data pattern, or a new failure mode. The feedback loop is structurally wider, and it runs whether or not your team is paying attention.
- Every client makes the system better for the next one. Each new implementation surfaces edge cases, classification failures, and taxonomy patterns that feed back into the platform. A vendor who has processed millions of interactions across dozens of companies has a training signal no single internal build can replicate. The system you buy today is already the product of that accumulated learning.
- Experience doesn't transfer in. Knowing which taxonomy structures hold up over time, which enrichment approaches degrade at scale, which integrations break silently and why: this is knowledge that accumulates through repetition across many implementations. A team building for the first time starts from zero. A vendor who has done it dozens of times brings that pattern library with them, and applies it from day one.
The build math tends to price the construction. It rarely prices the gap between what a first implementation produces and what a mature, continuously optimized system produces.
Where Zefi fits
Zefi is built for precisely the substrate that breaks internal builds after the first demo, so your team can spend its engineering and AI capacity on the differentiated layer instead of rebuilding the foundation.
Centralize: Feedback from help desks, surveys, public reviews, CRM notes, call transcripts, app stores, and chat, unified into one analytical layer, connected, normalized, and deduplicated so the trend lines reflect reality.
Structure: A governed taxonomy shaped around your product language rather than a generic template, with sentiment, intent, and request/bug markers, versioned and consistent, so comparisons across periods, channels, and segments actually hold.
Analyze: Dashboards for frequency, sentiment, and trend, with breakdowns by source, country, and segment, plus a natural-language interface that lets any stakeholder query the full dataset without learning a dashboard.
Act: Alerts on emerging issues, insight pushed into the tools teams already use, and a Customer Intelligence layer that ties feedback to revenue, ACV, and account health, so decisions are weighted by business impact, not volume.
This core infrastructure enables five modules that teams can activate independently:
- Quality Assurance — AI evaluation on 100% of conversations, against custom scorecards
- Survey — CSAT, NPS, CES, in-app and link surveys, with AI-enriched responses
- Customer Intelligence — Full customer profile, AI health score, two-way CRM sync
- Opportunity — Product and service opportunities extracted from VoC, prioritized by ARR impact
- Brand Reputation — Public review monitoring, AI-powered reply, close the loop everywhere
The economics above are not incidental. Every client Zefi onboards improves the platform for all others. The infrastructure cost is distributed, the optimization expertise is accumulated, and the cross-company learning compounds over time. You inherit all of that from day one, without staffing for it.
| Capability | With Zefi | In-house build |
|---|---|---|
| Multi-source ingestion | Included across all major channels | Custom connector per source |
| Governed taxonomy | Structured, versioned, client-specific | Typically ad hoc, drift-prone |
| PII & access control | Built in | Designed and audited separately |
| Sentiment & intent | Automatic on every interaction | Prompt engineering + eval infra |
| Conversational access | Grounded, cited, permission-aware | Requires RAG, grounding, citations |
| Customer context joins | Feedback tied to CRM, ACV, health | Warehouse work + identity resolution |
| Ongoing maintenance | Handled by the platform | Permanent cross-functional team |
| Time to value | Weeks | Quarters to years |
A member of our team will get in touch soon


Extract value from user feedback
Unify and categorize all feedback automatically.
Prioritize better and build what matters.